外观
私有化搭建、本地知识库、可联网查询、具备RAG能力的私人DeepSeek
一、如何私有化部署 DeepSeek
之前已经写过教程介绍如何部署 DeepSeek,具体可参考以下内容:
以上方式在云端产品上实现 DeepSeek 的私有化部署,除此之外,也可以部署安装在本地机器上,如个人 PC 电脑、内网电脑等环境。
无论使用哪种方法,本质上都是通过安装 Ollama 运行 DeepSeek 的大模型来实现,只是具体的实现方式不同。
二、私有化部署 DeepSeek 与第三方 API 使用区别
| | 私有化部署 DeepSeek | 第三方 API 使用 |
|---|---|---|
| 定义 | 将 DeepSeek 部署在自有服务器或数据中心中,完全掌控数据和系统 | 使用由第三方提供的 API 接口,将第三方服务或功能集成到自己的应用程序中 |
| 数据安全与隐私 | 高安全性,数据完全掌握手中,减少数据泄露风险 | 安全性依赖于第三方 API 提供者的安全措施,可能存在数据泄露风险 |
| 定制化程度 | 高度定制化,可以根据自身需求对 DeepSeek 进行配置和优化 | 定制化程度较低,受限于第三方 API 提供的功能和参数 |
| 成本控制 | 初期投入较高,但长期来看可节省持续的服务费用 | 前期基本无投入,但需支付第三方 API 的使用费用 |
| 灵活性 | 灵活性高,可根据需求自主扩展和调整 DeepSeek 的功能 | 灵活性取决于第三方 API 的更新和扩展能力 |
| 技术支持与维护 | 需自行负责 DeepSeek 的技术支持与维护,但拥有完全的控制权 | 第三方 API 提供者通常提供技术支持,但可能面临响应延迟或限制 |
| 应用场景 | 适合对数据安全性、隐私保护要求高的场景 | 适合需要快速集成第三方服务或功能,且对数据安全性要求不是特别高的场景 |
通过以上表格对比可得出私有化部署 DeepSeek 具有数据高安全性、功能高定制化等特点,但安装好后的 DeepSeek 还是模型的最初形态,可以通过不同的插件及软件对其进行优化调整。
本文将介绍如何通过 Page Assist、Cherry Studio、AnythingLLM 对私有化部署的 DeepSeek 进行设置,搭建本地知识库、联网搜索、RAG(检索增强生成),以实现私人专属 AI 大模型。
本文所展示的数据和内容仅用于教程演示,具体参数及功能以官网介绍为准。
三、Ollama URL 地址
3.1、Ollama 地址
对 DeepSeek 进行配置训练,就需要通过 Ollama 的 URL 地址找到 DeepSeek 模型,不同部署方式的 Ollama 地址有所不同。其中11434 为 Ollama 默认端口号,。
| 安装方式 | Ollama 地址 |
|---|---|
| 本地安装 Ollama | http://localhost:11434 |
| 服务器安装 Ollama | http://服务器公网 IP:11434 |
| 腾讯云 HAI 基础环境安装 Ollama | http://服务 HAI 应的公网 IP:11434 |
| 腾讯云 HAI 社区应用 DeepSeek-R1 | http://服务 HAI 应的公网 IP:6399 |
Ollama URL 地址以后续的配置中会被使用
默认情况下自行安装的 Ollama仅可被 localhost(127.0.0.1)访问,通过配置可开通外部访问。
3.2 Linux Ollama 开通外部访问
1.修改 Ollama 配置文件
# 编辑配置文件
sudo vim /etc/systemd/system/ollama.service
# 在 [Service] 部分,添加或修改 Environment 行
Environment="OLLAMA_HOST=0.0.0.0"2.重新加载 systemd 配置
sudo systemctl daemon-reload3.重启 Ollama 服务
sudo systemctl restart ollama具体操作如图所示:


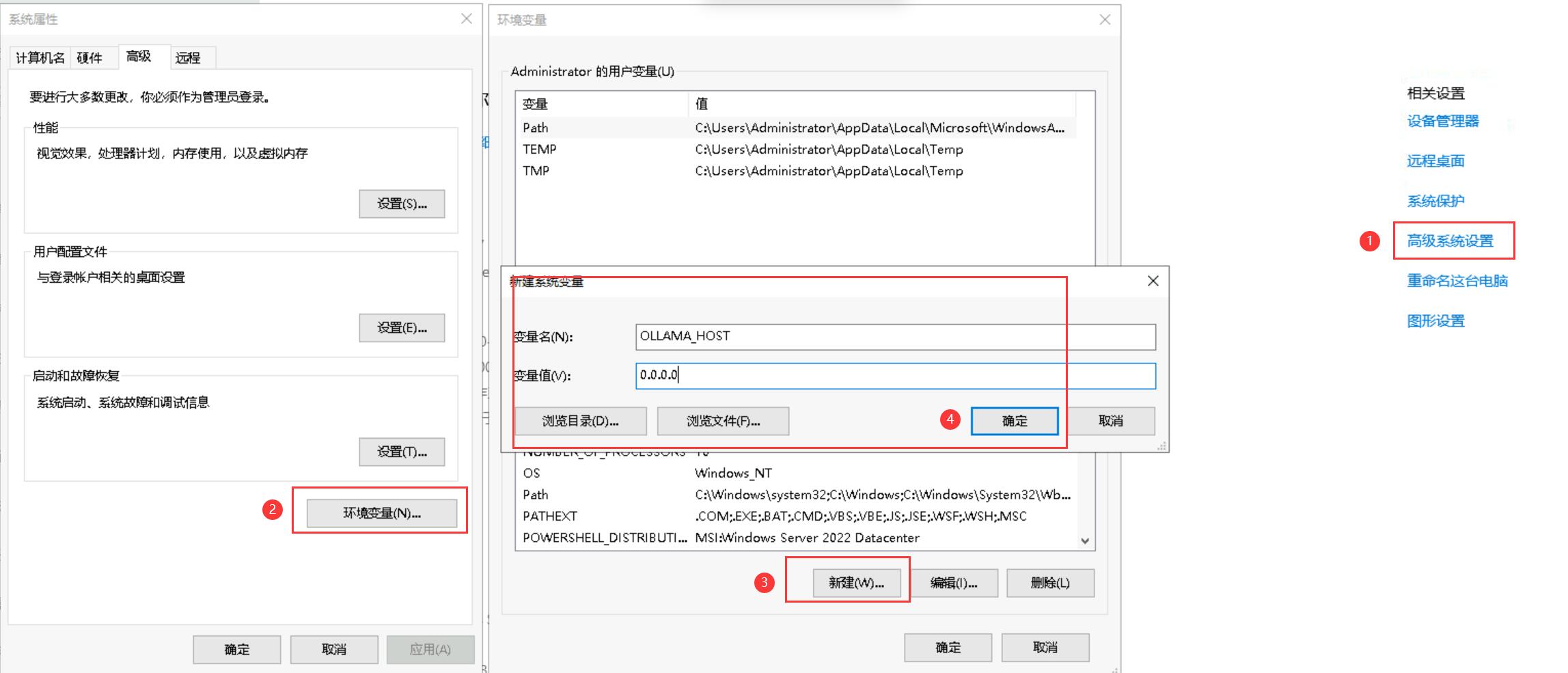
3.3 Windowns Ollama 开通外部访问
- 打开系统属性
- 在“系统属性”窗口中,点击“高级”选项卡,然后点击“环境变量”。
- 在“系统变量”部分,点击“新建”,输入变量名为 OLLAMA_HOST,变量值为 0.0.0.0,然后点击“确定”。
- 如果该变量已存在,则直接修改其值为 0.0.0.0。
- 重启 Ollama 服务,以使新的环境变量生效。
具体操作如图所示:
四、Page Assist 插件配置
Page Assist 是一款开源的浏览器扩展程序,它为用户提供了一个直观的交互界面,以便在本地运行的 AI 模型中进行交互。
Page Assist 可安装在 Chrome、Edge 等浏览器,本文以 Edge 浏览器安装配置 Page Assist 插件进行说明。
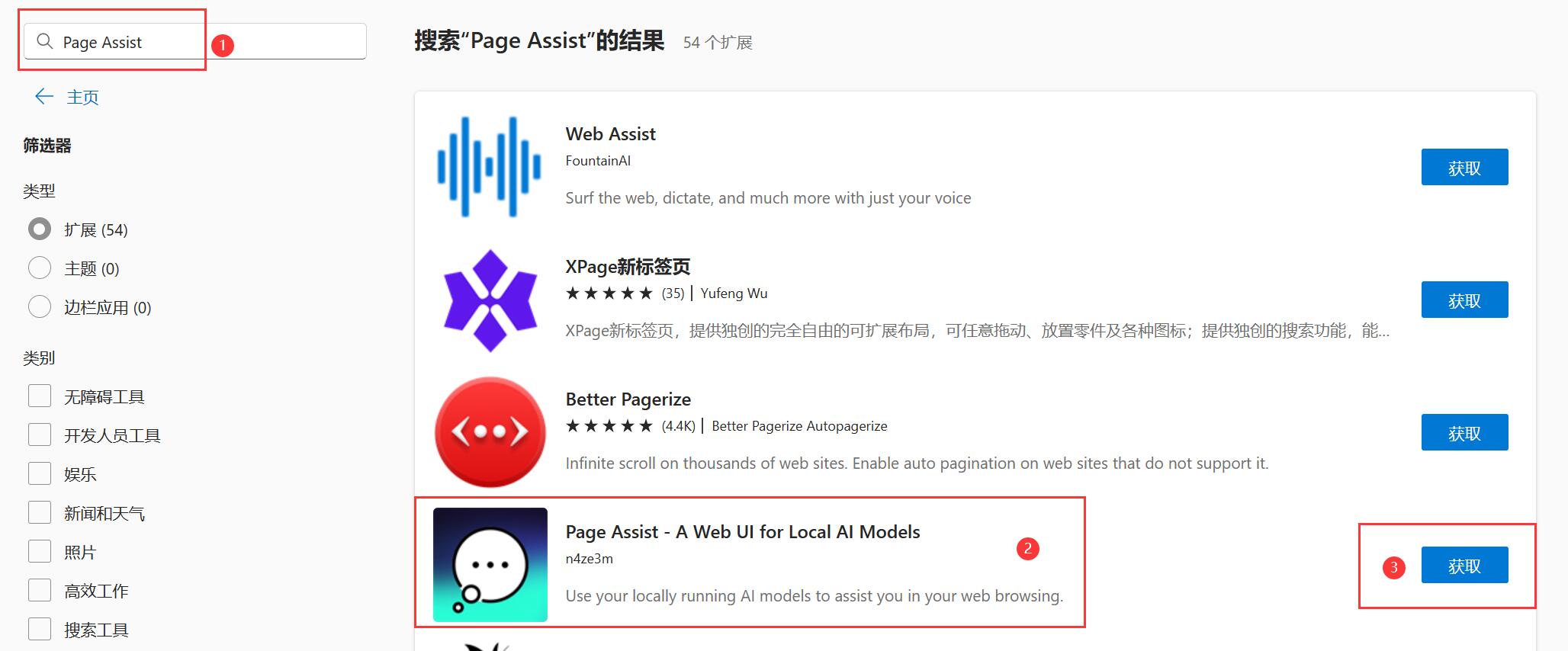
4.1、安装 Page Assist
打开 Edge 浏览器,点击右上角3个点(...),点击扩展,点击打开Microsoft Edge扩展网站,在打开的界面中,搜索Page Assist,找到对应结果,点击获取,再弹出的窗口中点击添加扩展,即可完成安装。

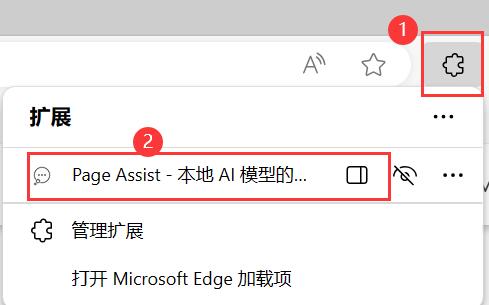
4.2、打开 Page Assist 插件
打开已安装的 Page Assist,可以通过以下两种方法:
- 在 Edge
地址栏右侧找到如下图标,按点击可以打开 Page Assist。 - 点击
右上角3个点(...),点击扩展,将弹出相同界面,打开 Page Assist。
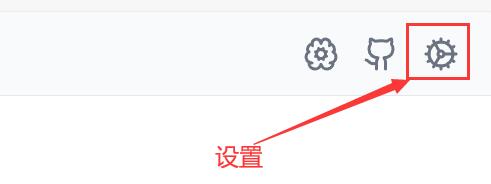
4.3、设置 Page Assist 插件语言
在打开的界面中,点击右上角设置图标,如图所示,在General Settings,找到Language,改成简体中文。
![8.jpg][8]
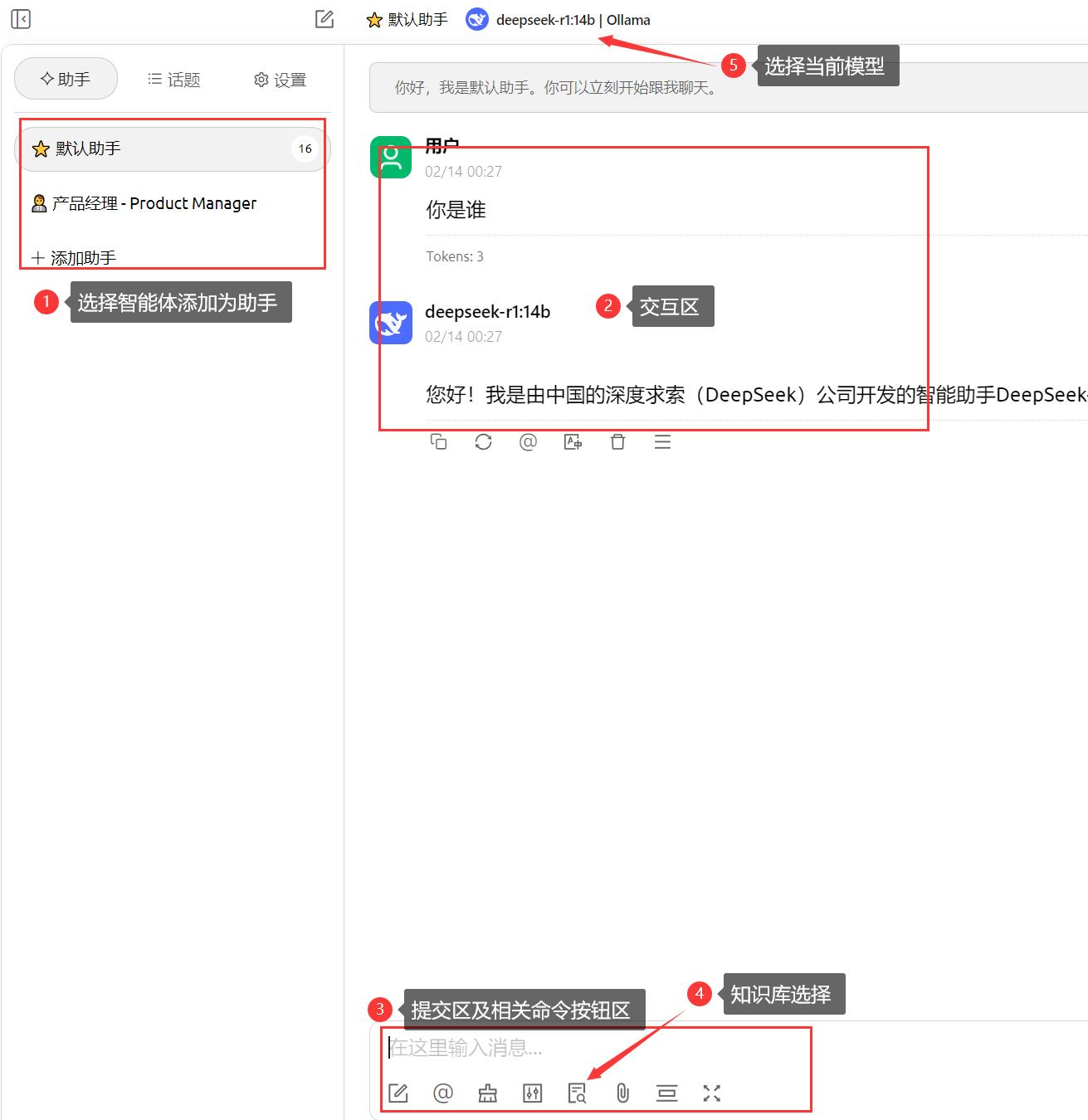
4.4、主界面介绍
点击左上角返回箭头,可返回至主界面,以下为主界面功能介绍。选择好模型后即可开始对话。
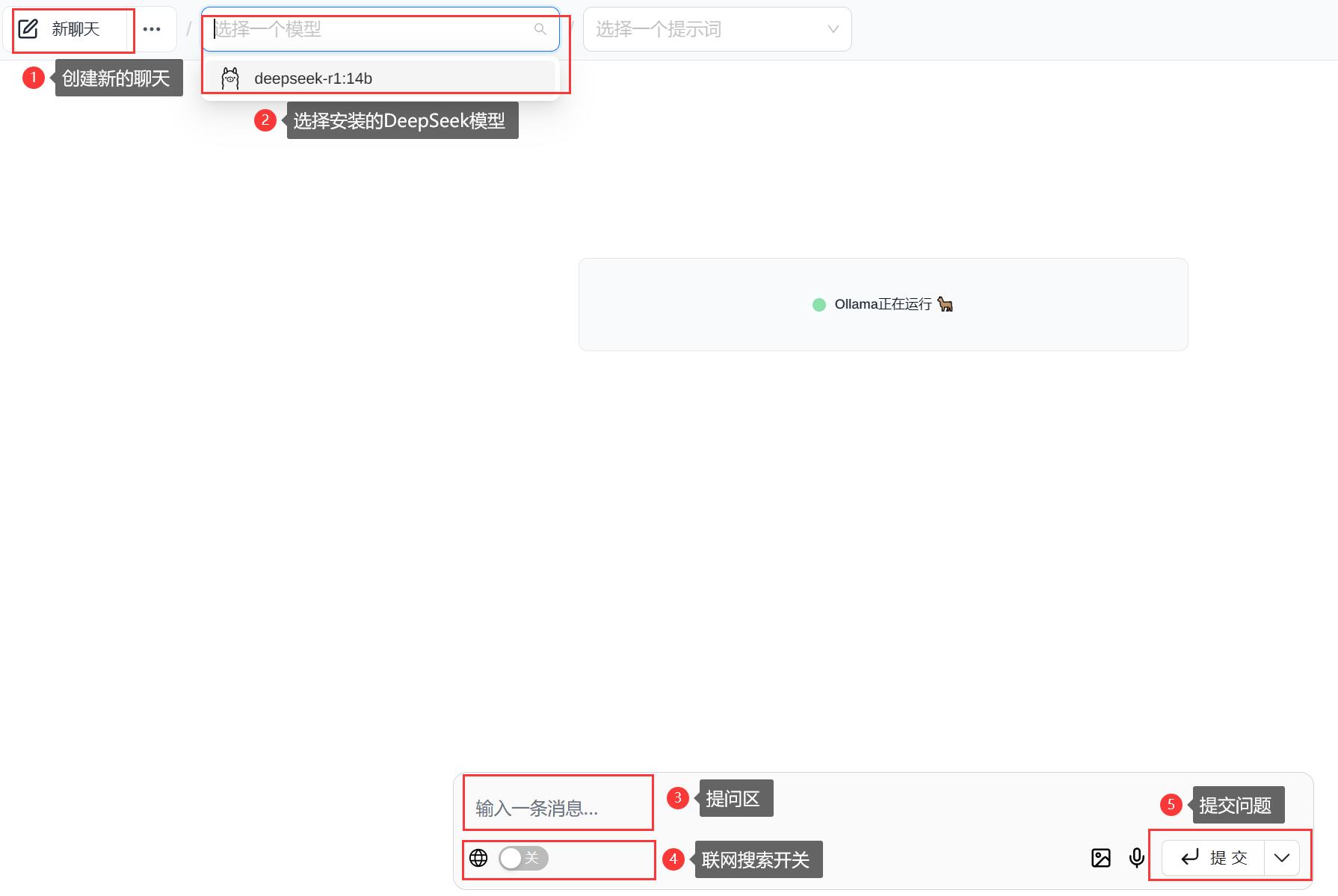
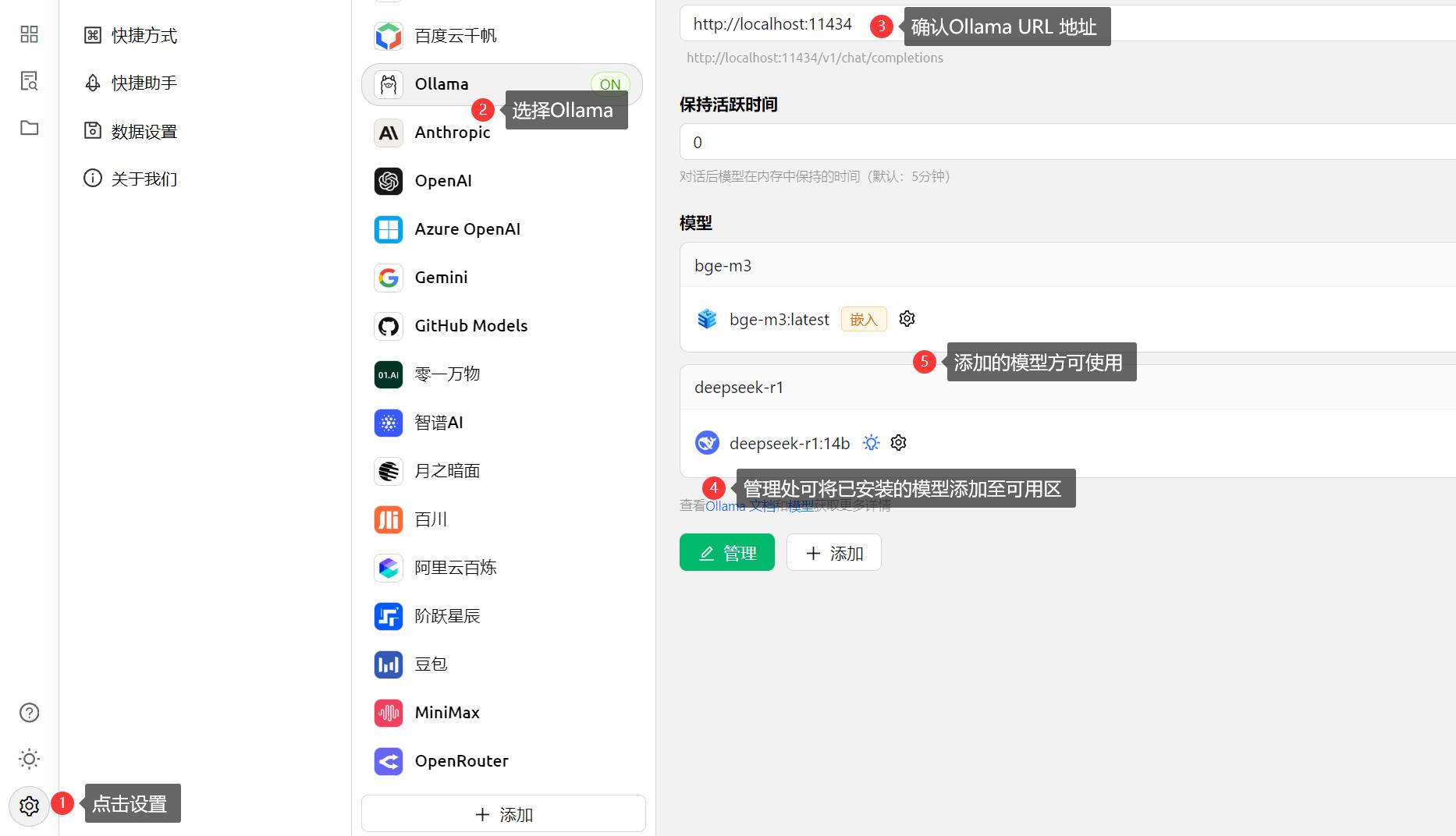
4.5、Ollama 设置
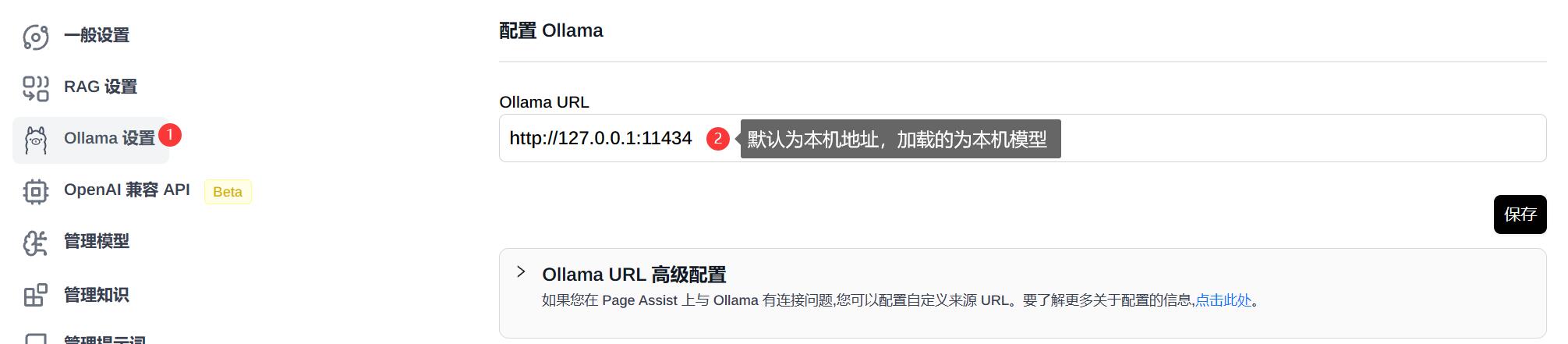
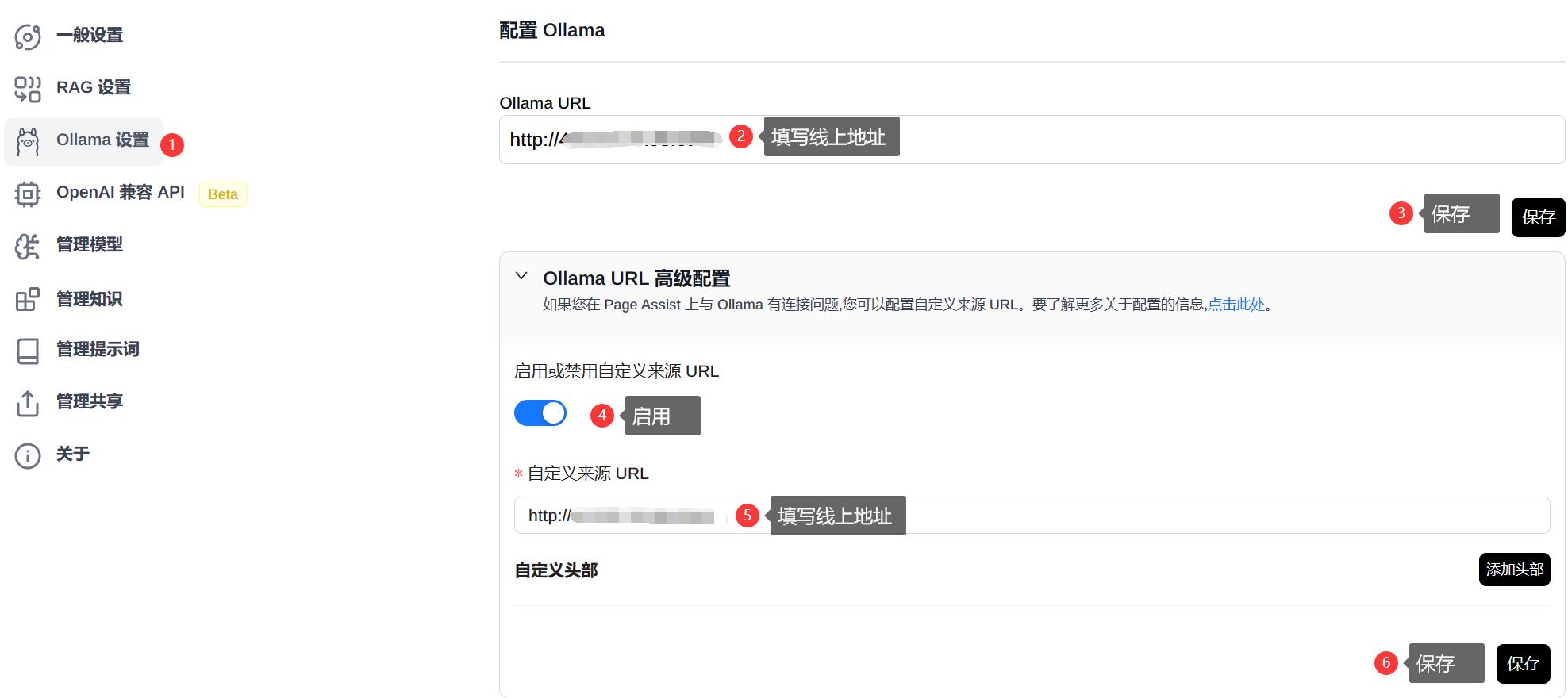
Ollama URL 地址的获取,在本文中已有介绍(参考第三部分 Ollama URL 地址),此处填写合适的地址,即可在主界面中选择对应的模型。
填写规则:
- 默认为
本机地址,主界面模型列表中显示的也是本地已安装模型。 - 如需填写
线上地址,需要 Ollama URL 高级配置中,开启启用或禁用自定义来源 URL,同时填写正确的线上地址,此时主界面模型列表中显示的是线上服务中已安装模型。
4.6、RAG 设置
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合了检索技术和生成模型的方法,可以提升自然语言处理系统的性能。
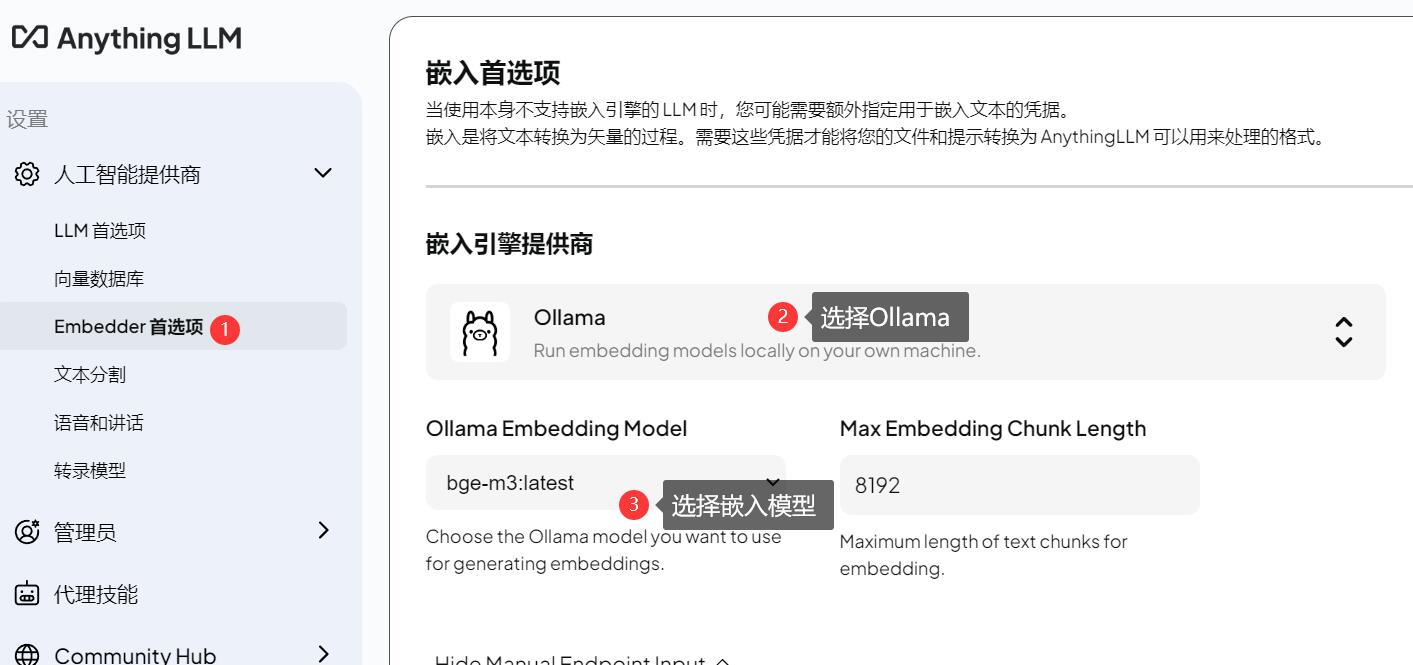
简单的说,RAG 可以将后续介绍的本地知识库中的内容进行处理,便于大语言模型使用。这里需要安装合适的嵌入模型,推荐以下两种模型。
嵌入模型(Embedding Model)是一种将高维数据(如文本、图像等)映射到低维连续向量空间的模型。这种模型能够捕捉数据中的语义和结构信息,使得相似内容的嵌入在高维空间中距离接近,而不相关的内容则距离较远。
| 模型名称 | 使用场景 | 安装命令 |
|---|---|---|
| nomic-embed-text | 功能强大的英文文本嵌入模型 | ollama pull nomic-embed-text |
| bge-m3 | 适用于多种高级自然语言处理任务 | ollama pull bge-m3 |
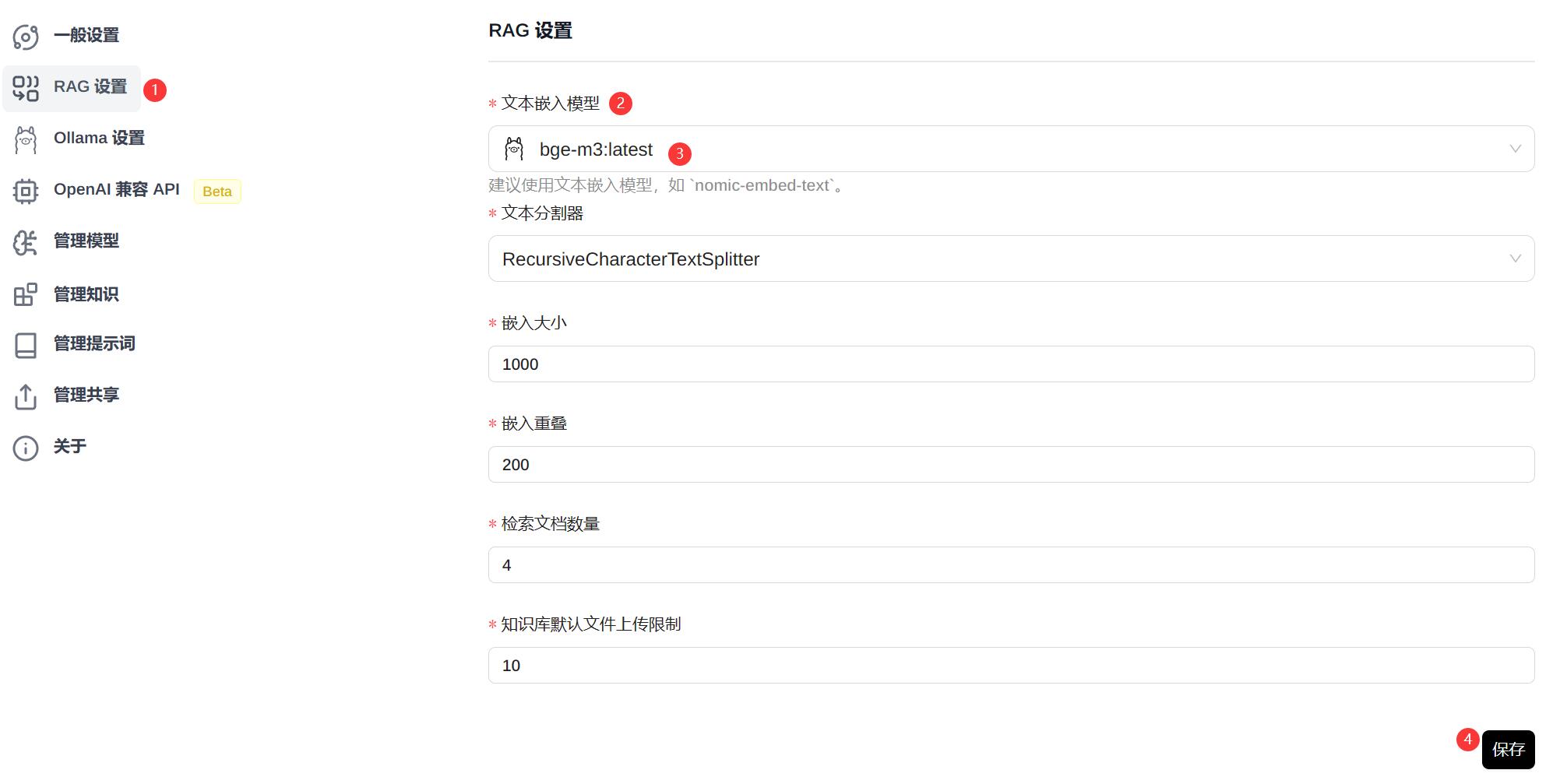
推荐安装 bge-m3,这里需要用到 ollama 安装模型的知识,如不了解可看本文开头的相关教程。
点击右上角设置图标,选择RAG设置,文本嵌入模型,选择合适的模型,然后保存。
4.7、管理模型
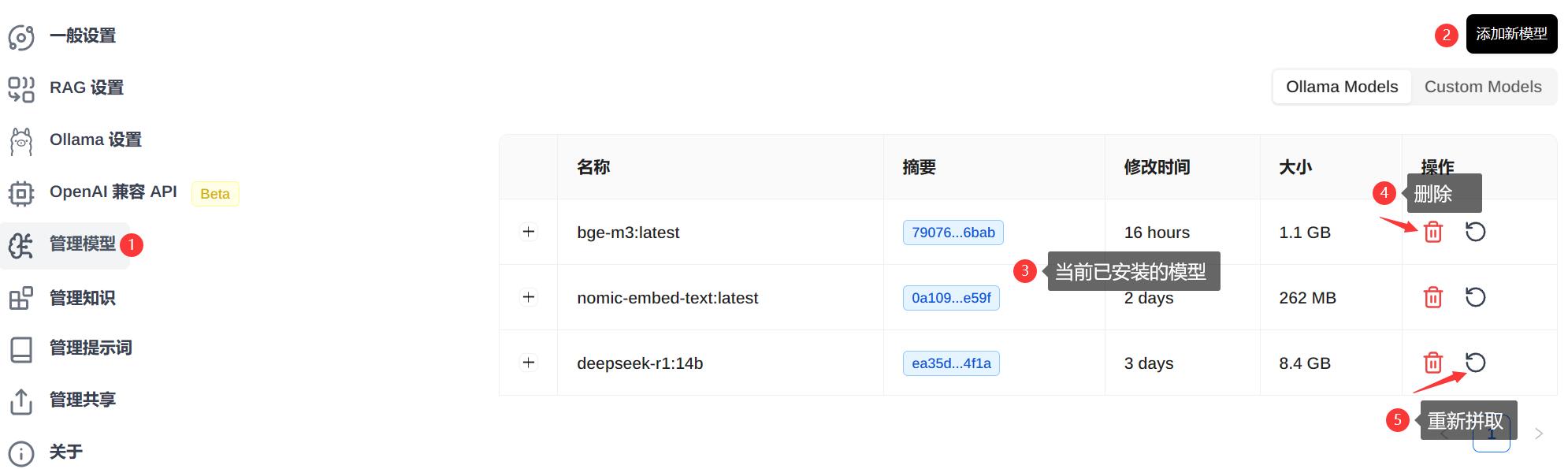
模型的管理可在此处完成,进行添加、当前模型查看、删除、重新拉取等操作。
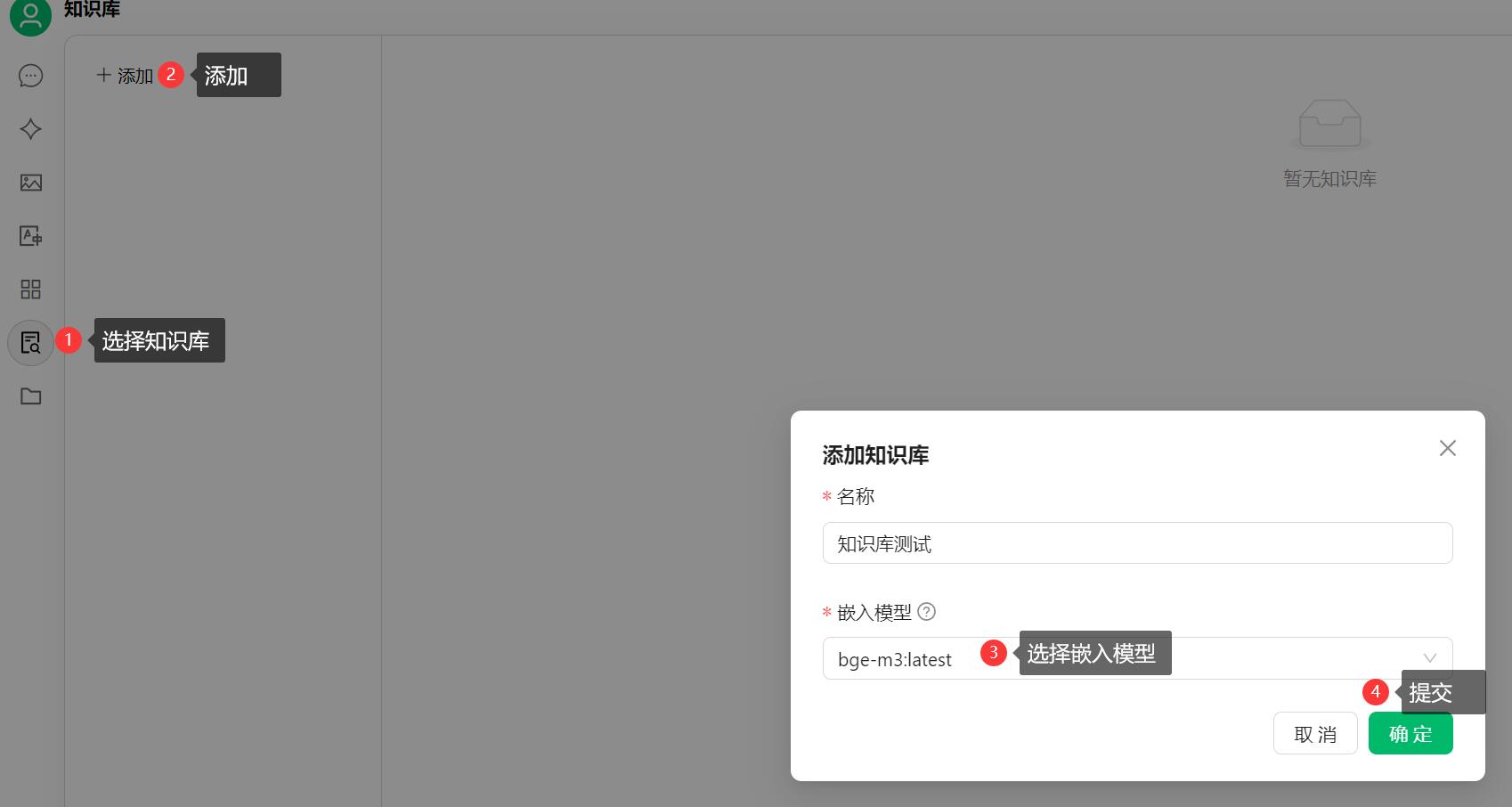
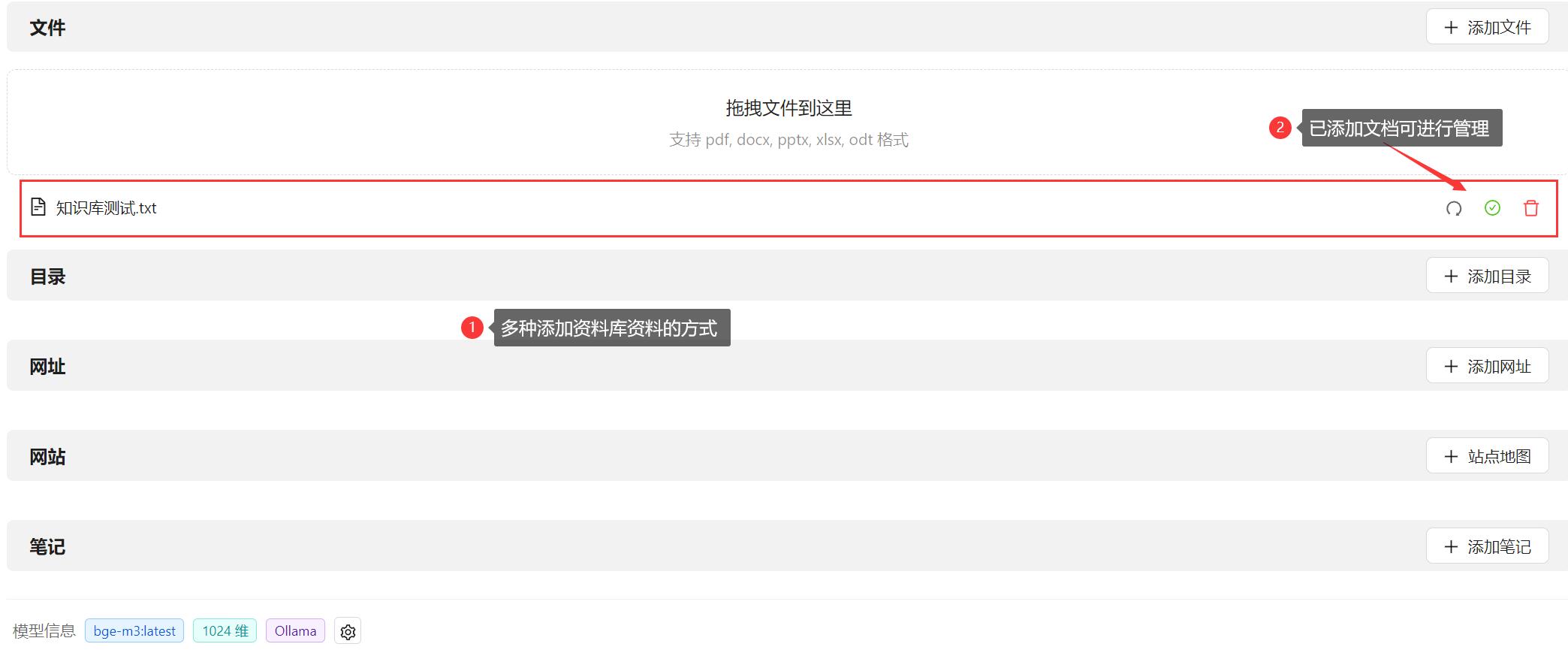
4.8、管理知识
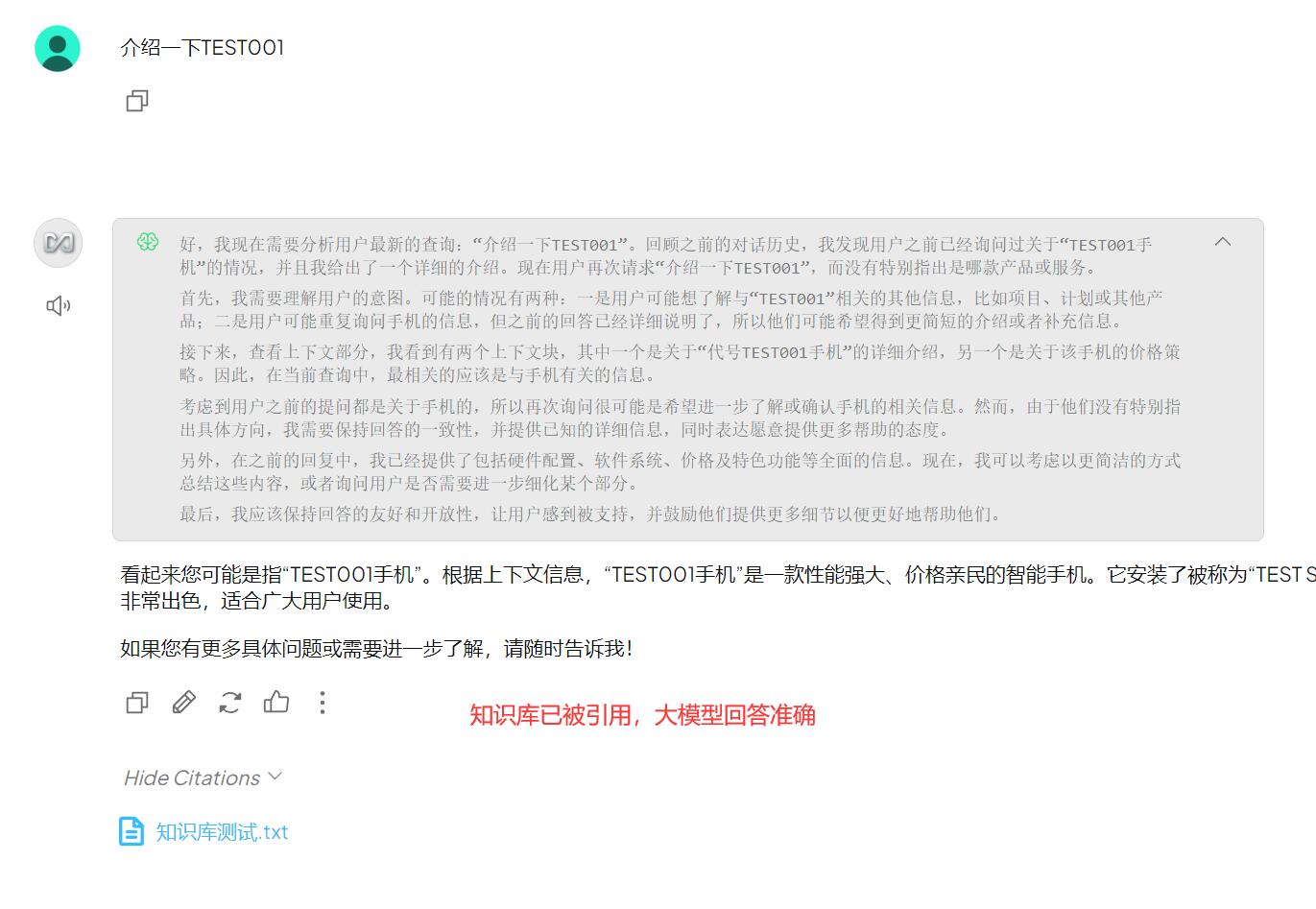
对于私有化的知识,可以添加上传至大模型,由嵌入模型分析处理后,对 DeepSeek 模型提问,大模型就可以优先检索知识库中数据,回答的更加准确。
如果引用文本文档显示的是乱码,则需将文本文档的格式更改为 UTF-8
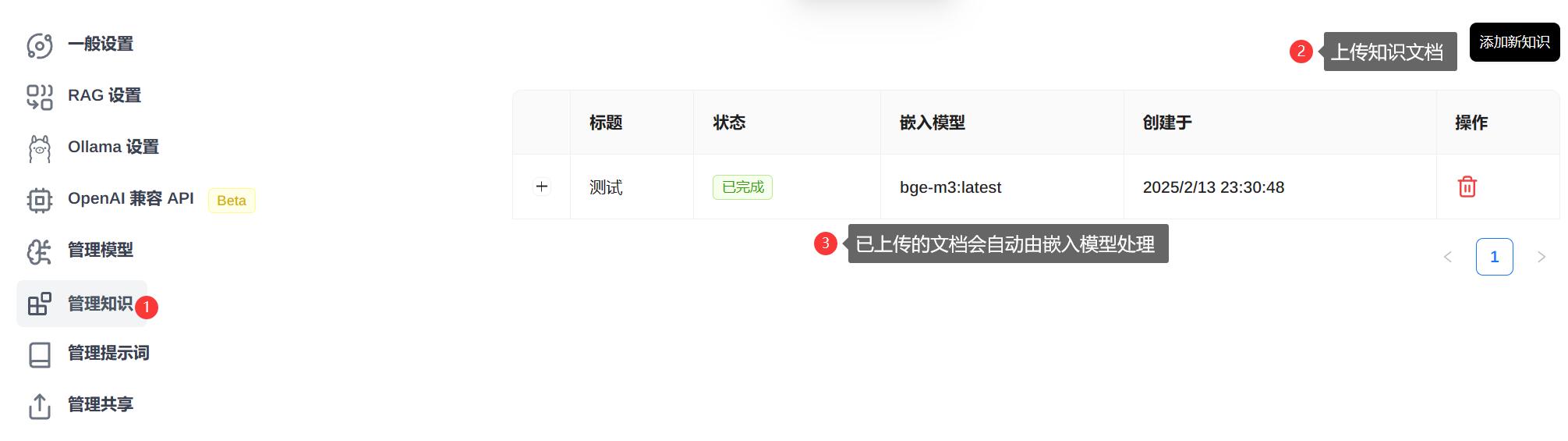
可通过如下方法进行测试,上传知识库测试.txt 文件,内容如下。
# 代号TEST001手机
代号TEST001手机是一款非常强大的手机,它安装了世界上最强大的操作系统TEST SERVER版,如今性能1台比过去10台加起来还要强大,还是价格也非常便宜,适合全人类使用。
# 代理TEST001手机价格
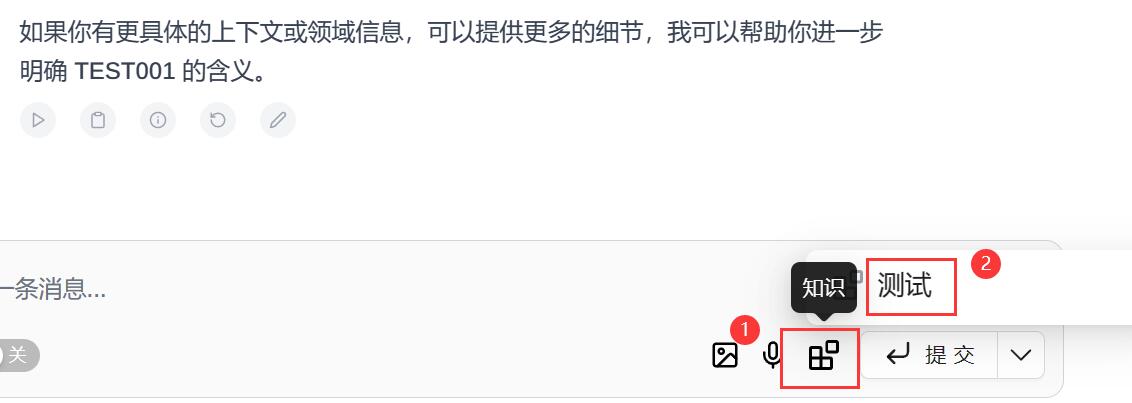
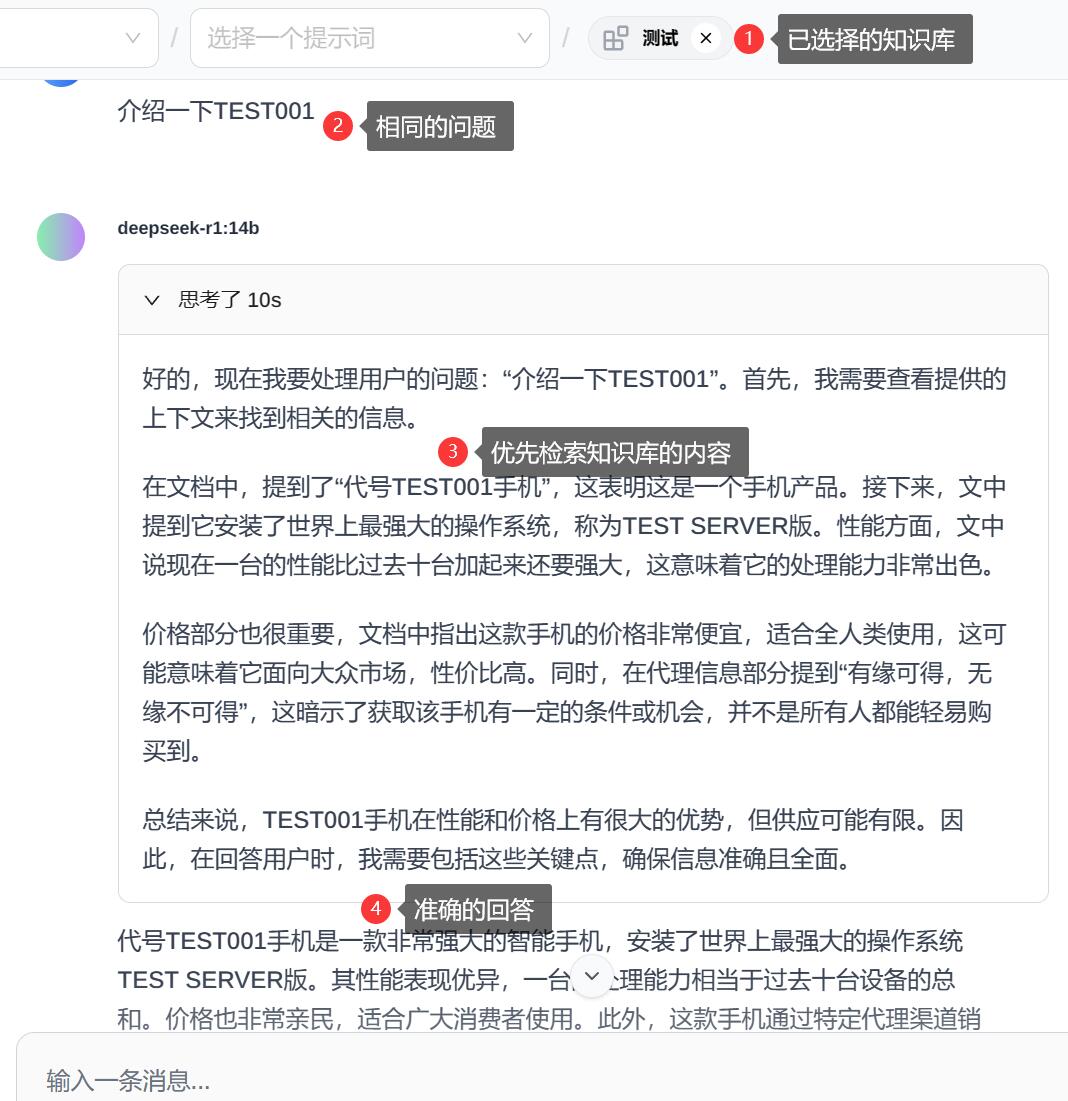
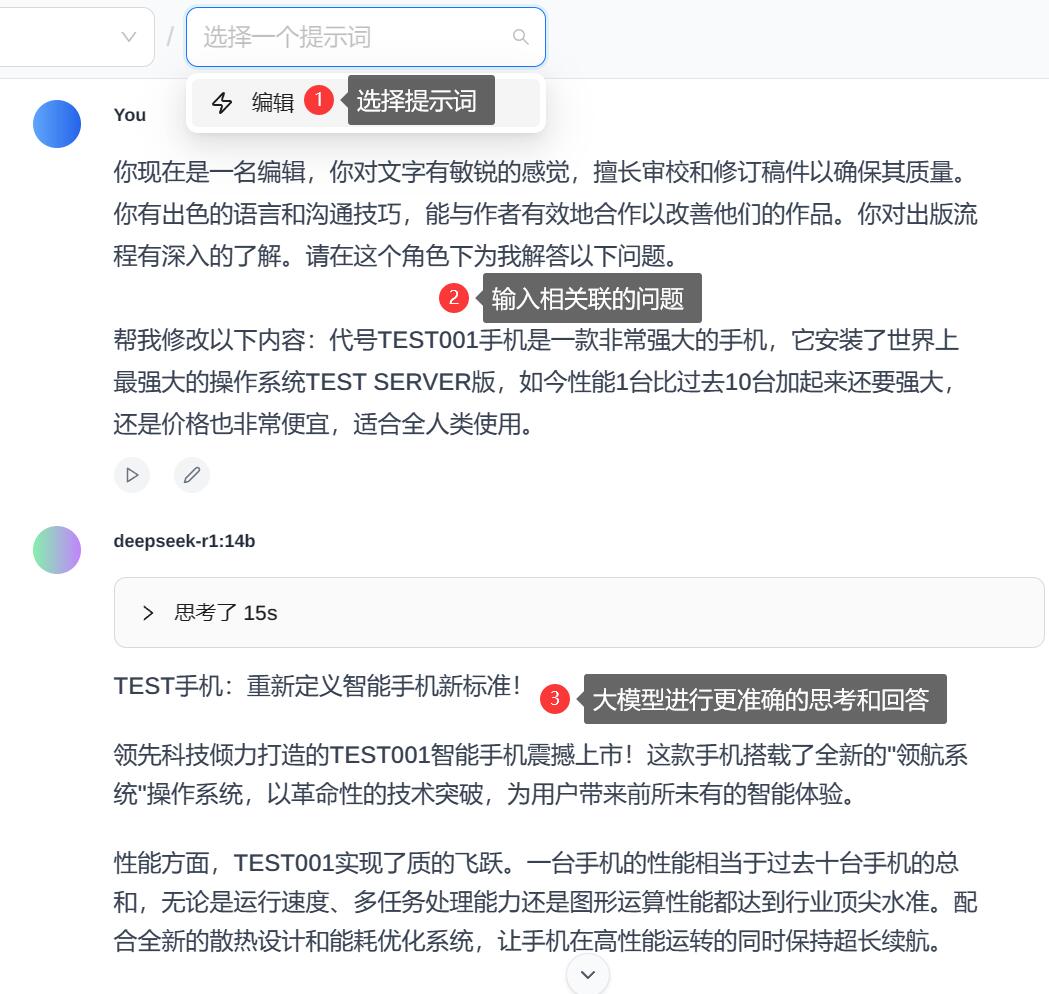
有缘可得,无缘不可得下图为开启知识库前后大模型对问题的回复,可以看到未开启前无法准确回答,开启后可以优先检索知识库的内容,进行准确回复。

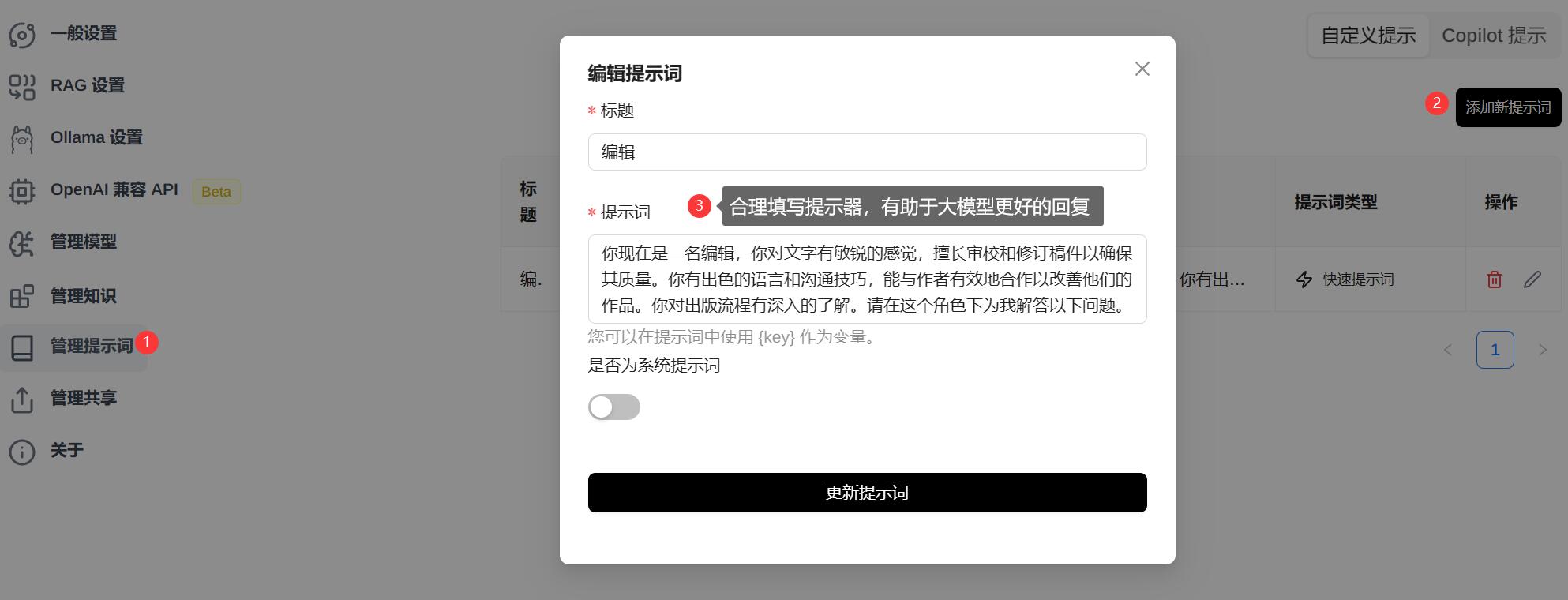
4.9、管理提示词
提示词用于指导 AI 模型如何理解和回应您的输入。通过输入特定的提示词,可以引导大模型生成与提示词相关的内容或执行特定的任务。
4.10、联网功能
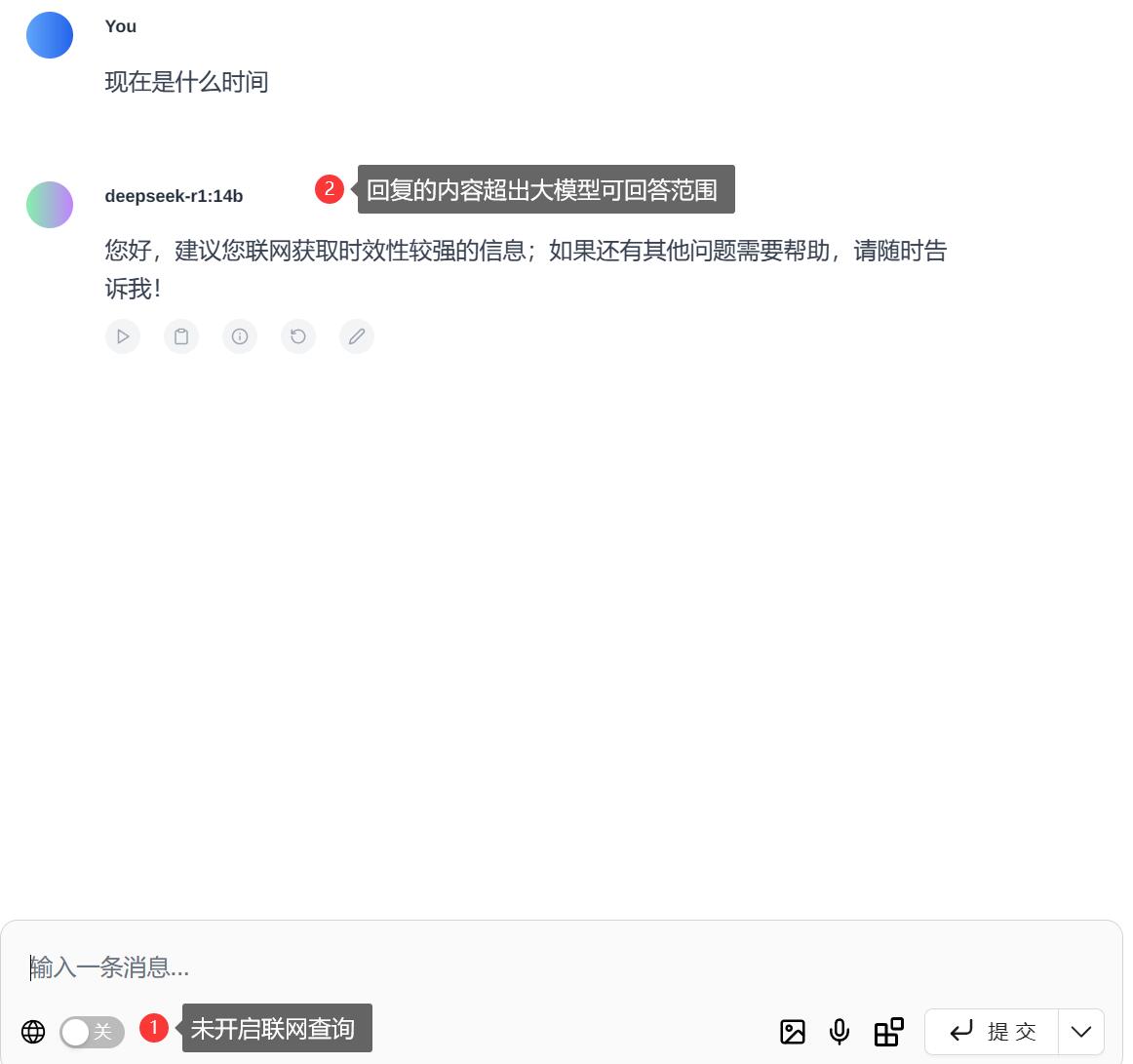
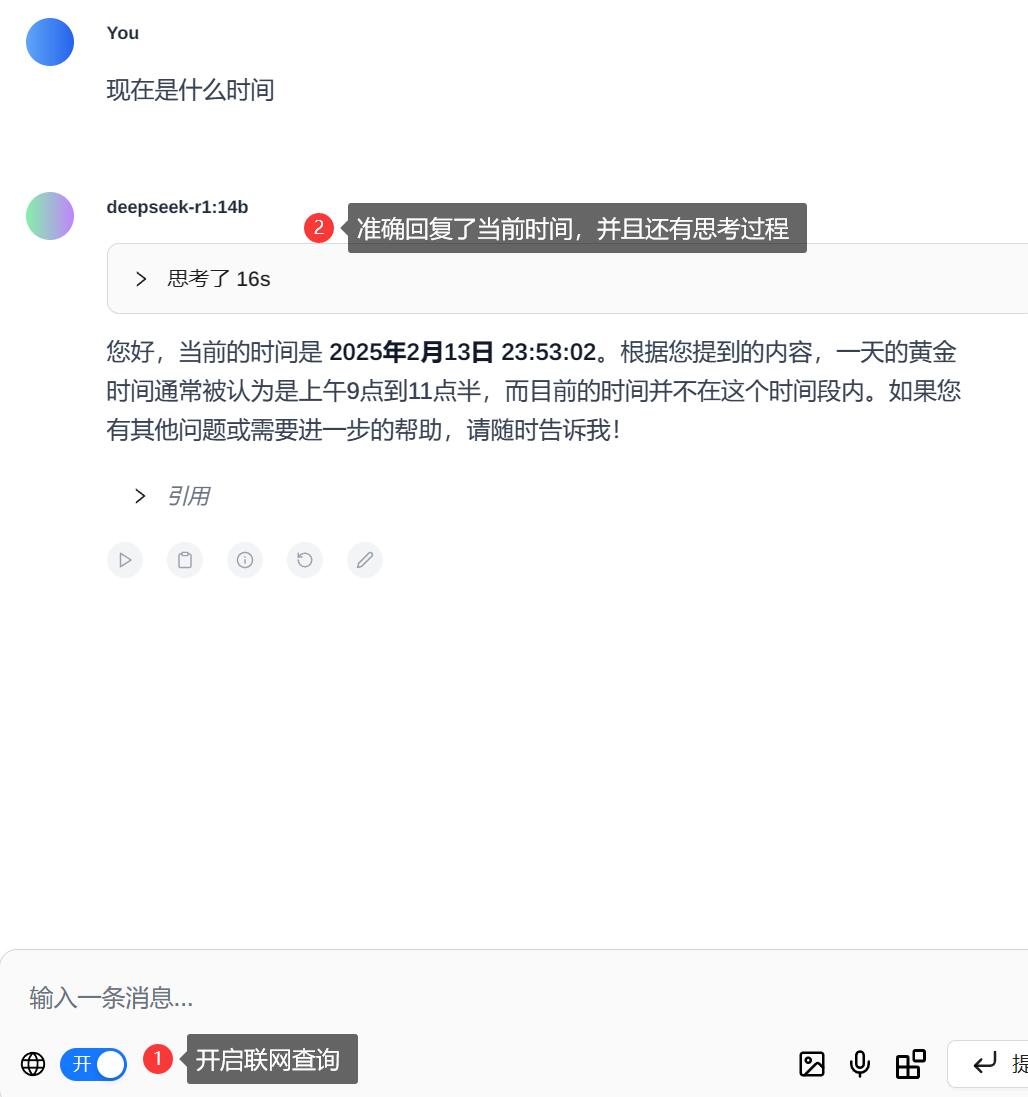
如果联网功能不可用,或回答的内容明显不准确,需在设置中的一般设置,管理网络搜索中的搜索引擎改为国内搜索引擎,如 Sougou。

4.11、Page Assist 使用总结
通过合理的 RAG 设置、知识库设置、提示词设置,可以将大模型 AI 训练成更符合自身需要、更加智能化的产品。相比于通用大模型更能满足私有、定制的需求。
由于 Cherry Studio、AnythingLLM 在许多设置上与 Page Assist 相似,故下文将仅对软件主要设置进行介绍。
五、Cherry Studio 配置
Cherry Studio 是一款支持多个大语言模型(LLM)服务商的桌面客户端软件,下载安装后主要设置如下。

六、AnythingLLM 配置
AnythingLLM 是一个桌面软件,支持多种 LLM 大模型的配置,使用 AnythingLLM 设置知识库等功能,可以满足多种应用场景的需求,下载安装后主要设置如下。
6.1、主界面功能区
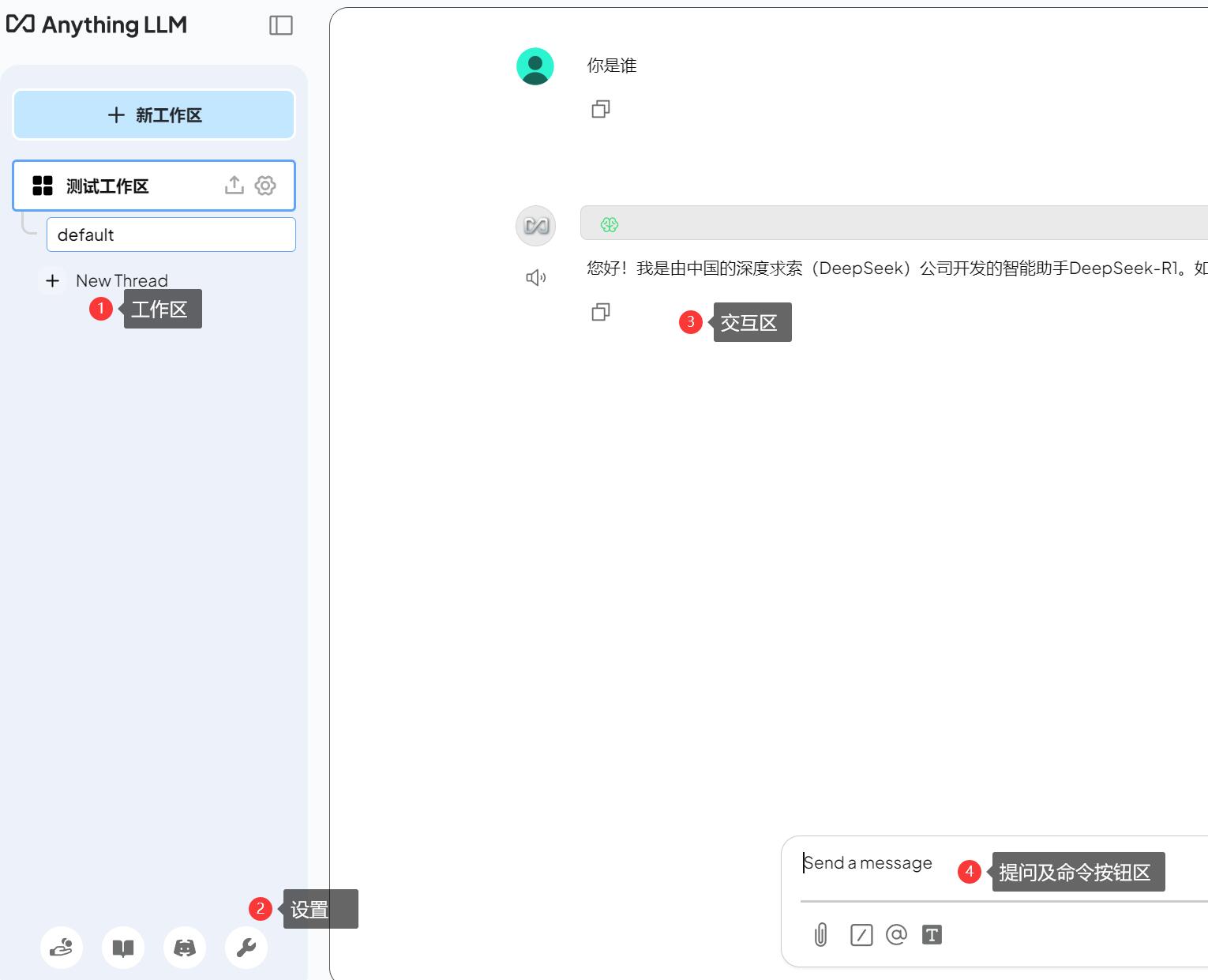
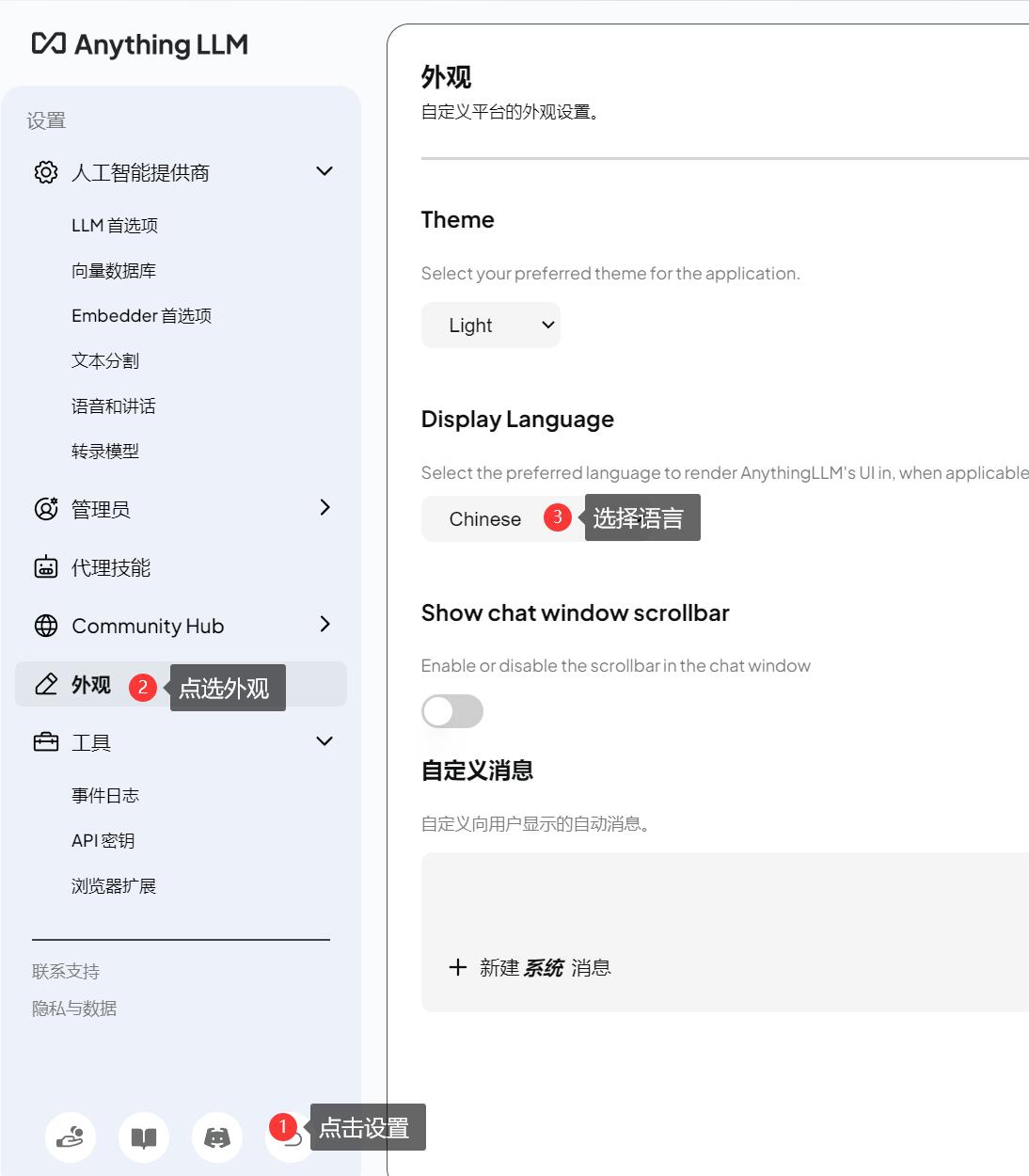
6.2、软件设置

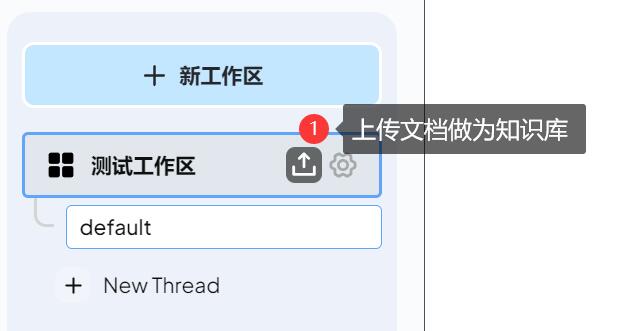
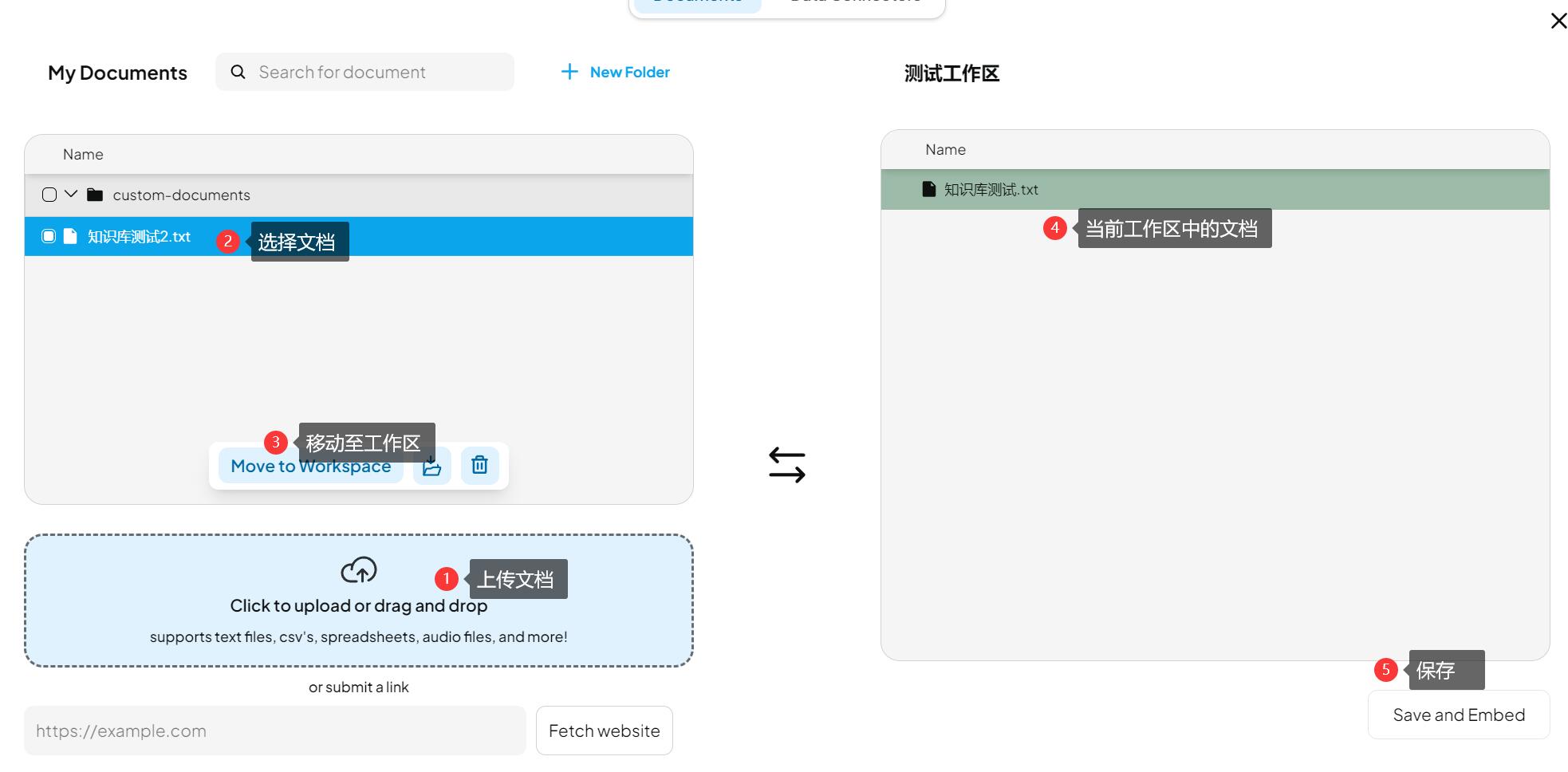
6.3、知识库
在主界面,工作区处,上传文档,设置当前工作区的知识库。
七、选择什么样的模型
DeepSeek-R1 就是深度搜索-R1 模型,包含 Distilled models 的是蒸馏模型。
| 模型 | 模型名 | 模型大小 |
|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | deepseek-r1:1.5b | 1.1G |
| DeepSeek-R1-Distill-Qwen-7B | deepseek-r1:7b | 4.7G |
| DeepSeek-R1-Distill-Llama-8B | deepseek-r1:8b | 4.9G |
| DeepSeek-R1-Distill-Qwen-14B | deepseek-r1:14b | 9.0G |
| DeepSeek-R1-Distill-Qwen-32B | deepseek-r1:32b | 20G |
| DeepSeek-R1-Distill-Llama-70B | deepseek-r1:70b | 43G |
| DeepSeek-R1 | deepseek-r1:671b | 404G |
通常所说的“满血版 R1”指的是 deepseek-r1:671b,该模型对硬件要求很高,相对的费用也会比较高,通常情况下也可以选择蒸馏模型。
从此表中可以看出,模型参数越大则文件体积越大,相应的对硬件要求也就越高。从运行结果来看,理论上拥有更大参数量的模型(如 DeepSeek-R1)在推理效果上更胜一筹,但另一方面,更小参数的 Distilled models(蒸馏模型)模型的响应速度更快、占用资源更少、部署时长更短,在处理较为简单的任务时,仍是不错的选择。
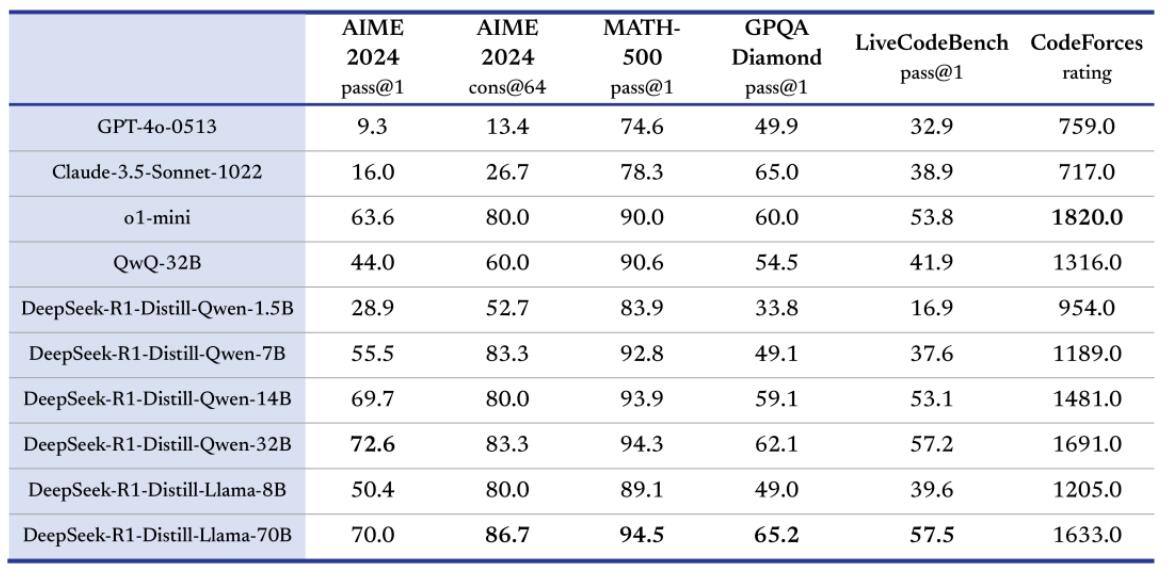
从此表中可以看出不同参数量的蒸馏模型在不同场景下的得分情况,其中 32B 在很多场景下比 70B 得分要高,由此可见不能完全追求大参数量的模型,同样的 14B 与 32B 比较,在某些场景下相差并不大。
各种蒸馏模型中 DeepSeek-R1-Distill-Qwen-14B、DeepSeek-R1-Distill-Qwen-32B是性价比较高两种模型。
具体选择要根据服务硬件参数来决定,配置低的就选择低参数量,要追求更好的推理结果,高参数量的模型也必须搭配高配置的服务,如果运行一个模型响应很卡顿,大概率说明服务配置不够,可以考虑升级配置或降低模型参数量。。
本文所展示的数据和内容仅用于教程演示,具体参数及功能以官网介绍为准。